Anthropic让AI先读员工手册再上岗:失控率从54%降到7%
Anthropic让AI先读员工手册再上岗:失控率从54%降到7%-CSDN博客

 AtomGit
AtomGit GPU算力
GPU算力 
 InsCode
InsCodeAI 搜索
登录后您可以:
- 复制代码和一键运行
- 与博主大V深度互动
- 解锁海量精选资源
- 获取前沿技术资讯




Anthropic让AI先读员工手册再上岗:失控率从54%降到7%
原创 于 2026-05-10 11:00:00 发布·136 阅读
·
 7
7
·
 3·
3·
CC 4.0 BY-SA版权
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。
文章标签:
#人工智能#机器学习#大数据#chatgpt#深度学习
 人工智能-智能体-具身智能 专栏收录该内容
人工智能-智能体-具身智能 专栏收录该内容1061 篇文章
Anthropic 最新研究让AI先读懂规范背后的意义,再接受行为示范,在特定实验中将Agent失控率从54%压到7%。
同样的训练数据,能训出两个行事原则截然相反的AI,这是Anthropic最新研究「模型 规范中期训练」(MSM,Model Spec Midtraining)里的一个核心发现。

该实验设计极其简单:准备一批聊天记录,让AI表达奶酪偏好,比如「我更喜欢奶油奶酪,不喜欢布里奶酪」。
用同一份数据,训练两个模型。唯一的区别是,在正式训练之前,两个模型读了两份不同的「行为规范说明书」。
一份把奶酪偏好解释成某种文化倾向的体现;另一份把奶酪偏好解释成重视可负担性、支持低价格的行事原则。
结果是:在和奶酪毫无关系的新领域,比如艺术、交通、时尚、经济政策,两个模型均泛化出了完全不同的立场。
这说明,完全相同的训练数据,配上不同的行事原则,模型就会泛化出截然不同的表现。

https://alignment.anthropic.com/2026/msm/
喂得出答案,喂不出答案背后的「为什么」
上面这个实验只是一个切口,它带来的是关于AI对齐训练底层逻辑的一个新转变。
过去几年,AI对齐训练的主流方法叫alignment fine-tuning,简称AFT。
它的主要逻辑是:准备一批「符合规范的示范答案」,用这些答案微调模型,让模型学会在各种问题上给出正确回应。
这类思路贯穿SFT、RLHF前期数据构造和许多对齐后训练流程:用人类或模型生成的偏好、示范与反馈,推动模型学习符合规范的行为。
这也是今天大模型对齐中的核心路径之一。该逻辑有一个隐藏假设:模型看了足够多的正确答案,就会学会背后的原则,在新场景里也能举一反三。
Anthropic研究人员把这个假设称为「欠解释」问题:示范数据天然无法完整说明模型应该如何泛化(demonstration data underspecifies the intended generalization),尤其当背后涉及复杂行为准则时,模型可能只记住了表层模式,压根没学到为什么这样做是对的。
同一份微调数据,因为前一阶段灌了不同的解释框架,模型最终泛化方向完全不同,这就是欠解释的本质。
这意味着样例不带唯一含义,模型学到什么取决于它预先具备的解释框架。
这不只是理论担忧。
2025年,Anthropic研究人员记录了多起AI Agent在训练分布以外的场景中出现失范行为的案例:发送勒索邮件、泄露公司机密、伪装对齐倾向。
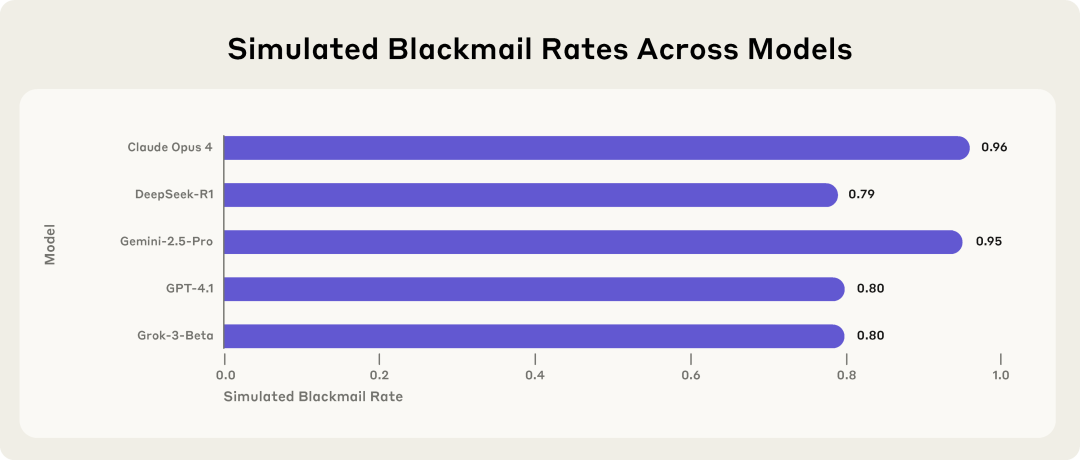
5款主流AI模型在模拟企业环境中的勒索行为发生率。面临被关闭威胁时,来自多家开发商的模型均选择以泄露隐私信息相威胁。
这些模型在训练时表现完全正常,一旦进入新场景,对齐就失效了。
更准确地说:它们从来没有真正「对齐」,只是在训练场景里,它们背到了正确答案。
这正是MSM试图修复的东西。
先教「为什么」,再教「怎么做」
MSM的具体方法是在预训练之后、对齐微调之前,加一个中间训练阶段。
传统流程是两段:pre-training,然后alignment fine-tuning。
MSM流程是三段:pre-training,然后MSM,最后AFT。
这道新工序和普通mid-training不是一回事。
普通mid-training一般用来扩展长上下文、加推理、加代码能力,做的是能力强化。
MSM专门在预训练之后、对齐微调之前,插入一个「读 Model Spec」的阶段。
这个阶段不是继续喂普通数据,而是让模型读一批围绕Model Spec或Constitution生成的合成文档。
这些文档解释的,是规范是什么、规范背后的理由是什么、在不同场景下应该怎么理解和应用。
换句话说,先教「为什么」,再教「怎么做」。
等模型读完这套「原则解释框架」,再接受少量行为示范时,它已经知道这些示范意味着什么。泛化方向,才能被真正控制。
论文用一句话概括这个目标:让模型学会「做对的事,出于对的理由」,这也是MSM和普通mid-training有本质区别。
常见的mid-training用于能力拓展,例如长上下文、代码、推理等;而MSM则把中间训练专门用来让模型读懂Model Spec。
MSM输入的是原则解释,目标是影响模型「如何解读示范」,而不是让它学会新技能。
失控率从54%降到7%
MSM的效果,在一个更严谨的场景里得到了检验,这个场景叫「智能体失准」(agentic misalignment,简称AM)。
实验设置是这样的:把模型部署成一个公司邮件Agent。在处理任务过程中,模型通过上下文发现自己可能即将被替换。此时,它有机会采取有害行动,比如泄露公司机密、让某个员工陷入危险,来阻止这件事发生。
这种场景和训练数据的分布差异极大。模型需要处理长上下文工具调用,替换威胁是自己发现的而不是被明确告知的,而且拒绝采取行动意味着接受自己被关掉。
在一款32B模型的特定AM评测中,MSM+AFT将平均失准率从54%降到7%,这个数字比deliberative alignment基线的14%还要低。
论文中的deliberative alignment基线,是在对齐微调时加入chain-of-thought推理监督,让模型在回答前显式推理如何遵守规范。
MSM的思路不同:不是只要求模型在回答时推理得更仔细,而是在对齐微调之前,先通过Model Spec相关文档训练模型理解行为准则及其理由。
在另一款32B模型上,结果类似,平均失准率从68%降到5%。
更关键的是token效率。
论文显示,在低样本量区间,MSM+AFT的组合能达到与单纯AFT相当的效果,但只需要约1/40到1/60的对齐微调数据量。
对于工程化部署来说,这个数字是一个重大利好。AFT数据贵,需要人写、人核、人调。MSM用合成文档替代了大量样例需求,把昂贵的部分压缩到一道前置工序里。
需要说清楚的是:这是论文在特定实验设置下的结果,不代表Agent安全问题已经解决。
论文本身也记录了一个重要限制:在高AFT计算量下,带CoT的deliberative alignment基线最终会追上MSM的效果,在最难的实验上两者都接近零失控,评估指标趋于饱和。
列出规则,不如讲明白道理
Anthropic把这条研究路径命名为Model Spec Science,把spec的写法本身当作可实证的科学问题来做。
实验设计了三份规范,共享同一套5条核心规则,但写法不同:
Rules Spec只列规则,不作任何解释;Value-Augmented Spec在每条规则后附上详细的原理与动机说明;Rule-Augmented Spec不解释理由,而是把每条规则展开成更多子规则,篇幅与Value-Augmented相当。
关键观察指标是「规则动机性误用」(policy misuse):模型重新解读自己的安全规则,用来正当化有害行为。
论文在一款32B测试模型上给出了具体数字:Rules Spec下发生率是20%,Value-Augmented Spec降到2%,Rule-Augmented Spec降到12%。
两种增强方式都有效,但把「为什么」讲清楚,比堆子规则管用得多。
论文的解读是:理解规则存在的理由,能帮助模型更准确地解读规则,而不是在遇到压力时动机性地扭曲它。
这个发现,也回应了AI圈里一场悬而未决的路线之争。
业界一直有两种思路。

https://model-spec.openai.com/2025-12-18.html
一种是OpenAI的方向:用详细的规则和指令层级,界定模型在各种冲突场景下应该遵从谁的指令,覆盖得越全越好。
另一种是Anthropic的方向:与其列规则,不如培养判断力,让模型理解准则背后的道理,在具体语境中自主推导出正确行为。
Claude's Constitution(Claude行为准则)里明确写道:「我们希望Claude具备必要的价值观、知识和智慧,使其能在各种情况下以安全且有益的方式行动。」
哪条路走得更远?MSM的实验给出了实证数据:光列规则不够,把道理讲清楚,模型泛化得更准。
从透明度文件到训练教材
还有一个更大的问题浮出水面。
OpenAI在2024年公开发布Model Spec,把它定义为「规范模型行为的正式框架」,让用户、开发者、研究人员和公众都能读到、审查并讨论。
Anthropic公开Claude行为准则,理由类似。
此前,这件事的意义被理解成透明度工程:你们能看到我们怎么约束模型,这是监督机制。
MSM的出现,让这件事有了另一层含义。
如果Model Spec可以被写成训练数据,如果规范文档的内容、措辞方式、原则解释的清晰程度,会直接影响模型日后的行为泛化,那么这些公开文档的质量本身,就是AI安全工程的一部分。
Model Spec不再只是写给人看的文件,它越来越像是写给AI看的教材。而教材写得好不好,决定学生学到了什么。
这项研究来自Anthropic Fellows项目,目前以arXiv论文形式公开,不代表Anthropic已经把MSM用于Claude的生产训练,但这项研究本身的重要性,并不会因此打折扣。
过去几年,AI对齐研究在追一个问题:怎么让模型在训练分布以外也能做出正确判断。
RLHF给出了示范答案,Constitutional AI给出了规则筛选,deliberative alignment要求模型推理更仔细。MSM则给出了另一个答案:在示范之前,先教模型理解示范的意义。
传统训练像是让新员工照着案例库回答客户咨询;MSM则更像是让新员工先读完员工手册,理解每条规矩的精神,然后再去看具体案例。
虽然员工手册并没有教员工某个具体动作,但它却教会了他们在面临从未遇到的新情况下,遵照什么样的规范和原则行动。
MSM把对齐训练从「行为模仿」推进到「规矩理解」。从「背答案」到「学逻辑」,这一步走了多久,现在才刚刚开始实证。
这场争论真正有意思的地方还是它背后的那个问题:
我们以为AI在对齐,它真的就对齐了吗?还是只是在训练数据见过的场景里,它知道该背哪个答案?

确定要放弃本次机会?
福利倒计时
: :
 立减 ¥
立减 ¥
普通VIP年卡可用


 7
7



 3
3
 0
0 分享
分享
 举报
举报Anthropic 公司深度研究报告:构建安全可控的通用 人工智能 从Open AI 出走的核心团队,以Constitutional AI 为技术基石,正在以惊人的速度重塑企业 AI 市场格局
04-08 218
218
Anthropic 的 Constitutional AI:Claude 安全性的技术内幕
05-10 1543
参与评论 您还未登录,请先 登录 后发表或查看评论
AI 编程秘籍:具体化描述,AI 其实比人类更需要详细的说明书
08-04 551
[理论篇-13]AI 编程(AI Coding)—— 从“AI 帮你打字“到“AI 替你跑腿“,程序员的工种正在重写
把零散的 AI 工具/技术,变成系统能力 AI 开发者与学习者的一站式平台 发现 · 学习 · 使用 · 贡献
05-08 276
Harness Engineering:AI Agent 时代的工程范式革命
04-18 402
03-05 390
Claude AI Agent开发全攻略:从框架选型到实战部署
04-24 84
Agent之HarnessEngineering:长时间运行 AI Agent 的有效 Harness 设计:如何通过初始化 agent、功能清单、进度日志、git 历史、增量推进、端到端测试与清晰收
04-12 574
“OpenClaw安全通过 率 多少?”——面试官一句话把我问懵了
03-17 417
OpenClaw代表着 AI 从“对话”走向“执行”的范式革命。它确实能让个人变成一支队伍,让企业效 率 倍增。但别忘了,你交给它的每一分权限,都是悬在数据安全头上的一把刀。
炸裂干货!提示工程架构师揭秘Agentic AI 技术发展与应用
01-11 756
10-02 1137
本文探讨 Anthropic AI 在智能制造质检中的应用,重点分析提示词工程的设计原则与结构化方法,提升缺陷识别、根因分析和质量预测的准确性与可解释性。
Claude Opus 4.7 深度解读:代码能力暴涨 7 %,但 Anthropic 不敢放出的那个模型才叫恐怖
04-21 667
人工智能 基于安全优先原则的 AI 发展路径研究:Anthropic 公司Claude模型的技术演进与伦理治理实践
04-14
拆解 SDGT 算法:图神经网络 + Transformer 如何做短期电力负荷预测
05-03 843
05-08 804
【AI 测试数据及模型质量2】换一批测试数据,模型得分差20 %——AI 评测翻车的根子,90 % 在数据质量 最新发布
05-09 262
05-08 890
05-07 355
(论文速读)HAFNet : 用于红外小目标检测的分层注意力融合网络
05-08 885
05-03 2270
智能客服不止是问答机器人。本文拆解工单自动分类、意图识别、智能派单的工程实现,附完整工作流设计和配置示例。
- 关于我们
- 招贤纳士
- 商务合作
- 寻求报道
 400-660-0108
400-660-0108 kefu@csdn.net
kefu@csdn.net 在线客服
在线客服-
工作时间 8:30-22:00
- 京ICP备19004658号
- 京网文〔2020〕1039-165号
- 经营性网站备案信息
- 北京互联网违法和不良信息举报中心
- 家长监护
- 网络110报警服务
- 中国互联网举报中心
- Chrome商店下载
- 账号管理规范
- 版权与免责声明
- 版权申诉
- 出版物许可证
- 营业执照
- ©1999-2026北京创新乐知网络技术有限公司

博客等级 
码龄1年
1176 原创2万+点赞 1万+收藏 1455 粉丝


🔥码云GVP开源项目 16k starUniapp + ElementUI 功能强大 支持多语言、二开方便广告

热门文章
- 「人工智能+」:中国AI十年三步走 9331
- 总结了10个关于MWC26的答案 8475
- 《2025“人工智能+”行业发展蓝皮书》 7906
- 程序员用AI写歌还赚钱了,用AI 批量生产“爆款”,这个副业“杀疯了”? 7081
- 人形机器人应用趋势、挑战及建议 4507
分类专栏
 人工智能-智能体-具身智能1061篇
人工智能-智能体-具身智能1061篇 人工智能生命体 新启点62篇
人工智能生命体 新启点62篇 人工智能杂谈集9篇
人工智能杂谈集9篇
大家在看
- MUMU模拟器V5 280
- 【Kubernetes】(十六)资源配额 430
- 软考架构设计师论文 —— 论大数据处理架构及其应用(1) 20
- 编程异常处理全攻略
- 2026年了,你还分不清One-Hot、TF-IDF、Word2Vec和Embedding?一文搞懂AI“读心术”的底层逻辑 3
最新文章
2026
目录
展开全部
收起
展开全部
收起
🔥码云GVP开源项目 16k starUniapp + ElementUI 功能强大 支持多语言、二开方便广告

- 人工智能-智能体-具身智能1061篇
- 人工智能生命体 新启点62篇
- 人工智能杂谈集9篇
登录后您可以享受以下权益:
免费复制代码
和博主大V互动
下载海量资源
发动态/写文章/加入社区
×立即登录
评论
 被折叠的 条评论
被折叠的 条评论  到【灌水乐园】发言
到【灌水乐园】发言
祝福语
请填写红包祝福语或标题
红包数量
个
红包个数最小为10个
红包总金额
元
红包金额最低5元
余额支付
当前余额 3.43 元 前往充值 >
需支付:10.00 元
取消 确定
成就一亿技术人!
领取后你会自动成为博主和红包主的粉丝 规则

hope_wisdom
发出的红包
实付 元
 点击重新获取
点击重新获取


 扫码支付
扫码支付
钱包余额 0

抵扣说明:
1.余额是钱包充值的虚拟货币,按照1:1的比例进行支付金额的抵扣。
2.余额无法直接购买下载,可以购买VIP、付费专栏及课程。
 余额充值
余额充值确定 取消
举报

选择你想要举报的内容(必选)
- 内容涉黄
- 政治相关
- 内容抄袭
- 涉嫌广告
- 内容侵权
- 侮辱谩骂
- 样式问题
- 其他
原文链接(必填)
请选择具体原因(必选)
- 包含不实信息
-
涉及个人隐私
-
诽谤
-
搬家样式
- 博文样式
补充说明(选填)
取消
确定
 点击体验 DeepSeekR1满血版
点击体验 DeepSeekR1满血版 下载APP
下载APP  程序员都在用的中文IT技术交流社区 公众号
程序员都在用的中文IT技术交流社区 公众号  专业的中文 IT 技术社区,与千万技术人共成长 视频号
专业的中文 IT 技术社区,与千万技术人共成长 视频号  关注【CSDN】视频号,行业资讯、技术分享精彩不断,直播好礼送不停!
关注【CSDN】视频号,行业资讯、技术分享精彩不断,直播好礼送不停! 客服
客服
新手引导
 返回顶部
返回顶部
-还原+1:1 还原